
쿠버네티스 오브젝트 활용
[Inflearn Warm-Up Club - DevOps] 매일 1% 성장하기
- 쿠버네티스 오브젝트 활용
- Probe
- Configmap, Secret
- PV/PVC (Persistent Volume/Persistent Volume Claim)
- Deployment
- Service
- HPA
- 회고
쿠버네티스 오브젝트 활용
Probe
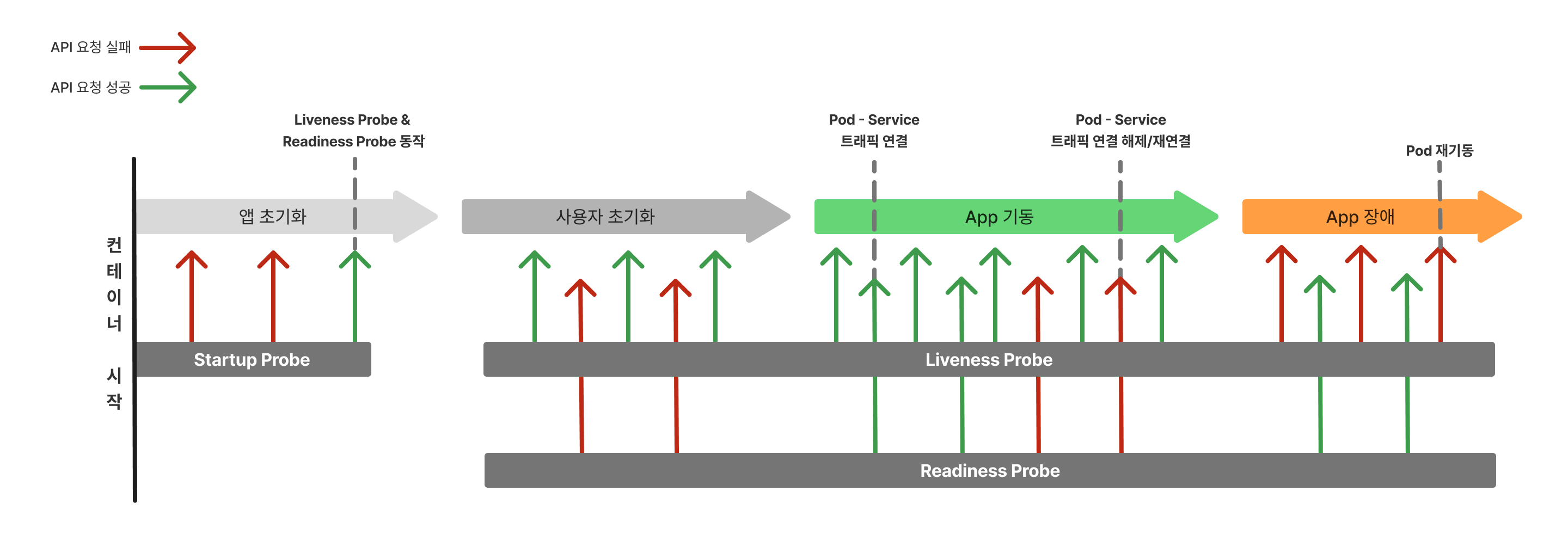
Kubernetes에서는 Probe를 통해 애플리케이션의 상태를 모니터링하고, 그에 따라 자동으로 재기동하거나 트래픽 연결 여부를 판단할 수 있다.
대표적인 Probe는 다음과 같다.
- StartupProbe: 애플리케이션이 초기화 중인지 확인 (초기 기동 상태)
- ReadinessProbe: 애플리케이션이 외부에서 트래픽을 받을 준비가 되었는지 확인
- LivenessProbe: 애플리케이션이 정상적으로 동작 중인지 지속적으로 확인
liveness와 readiness 차이
일반적으로 애플리케이션에 장애가 발생하면 liveness와 readiness가 모두 실패할 가능성이 크다. 그럼에도 불구하고 readiness를 사용하는 이유는 트래픽 제어 때문이다. livenessProbe는 앱이 살아있는지에 대한 여부만 체크하지만, readinessProbe는 서비스와의 연결 유무를 제어한다. 앱이 살아있어도 응답을 받을 수 없는 상태라면, readiness를 통해 트래픽을 잠시 끊어 앱을 보호할 수 있다. 이처럼 각 Probe마다 목적과 동작 시점이 다르기 떄문에 각각 다른 API를 사용하는것이 좋다.
Probe의 필요성
모든 애플리케이션은 기동 시 보통 다음과 같은 초기화 과정을 거친다.(Spring 애플리케이션 기준)
DB 연결 → Spring 초기화 → Jar 실행 → 사용자 정의 초기 데이터 로딩/외부 시스템 연동 등
이러한 과정을 수동으로 처리할 경우 직접 API를 호출해서 상태를 체크하고, 스케일 아웃이나 장애 발생 시 L4 라우터에서 트래픽을 수동으로 변경하거나 재기동 해야했다. 쿠버네티스의 Probe는 이러한 수동 작업을 자동화 해준다.
startupProbe
- 성공: 성공할 때까지 Service와 Pod를 연결하지 않음 → 기동 중인 상태 보호
성공 이후부터는 liveness와 readiness 동작
ReadinessProbe
- 성공: 서비스와 Pod 연결 (트래픽 허용)
- 실패: 서비스 연결 해제 (트래픽 차단)
livenessProbe
- 실패: Pod 강제 재기동
JVM 기반 애플리케이션은 기동 후에도 JIT 컴파일, 캐시 로딩 등으로 인해 성능이 일시적으로 불안정할 수 있다. 이런 웜업 구간 동안 트래픽 유입을 차단하기 위해 readinessProbe를 활용하는 것이 권장된다. readinessProbe가 성공할 때까지 서비스 연결을 보류함으로써 안정적인 트래픽 처리가 가능해진다.
장애상황에서 Probe 활용
일시적인 장애(예: Overload, Memory Leak, Thread Full 등)로 인해 livenessProbe와 readinessProbe가 모두 실패하면 Pod는 재기동된다. 하지만 Probe가 없었다면 시간이 지나 정상으로 복구될 수 있었던 상황일 수도 있다.
이때 readinessProbe는 실패 시 외부 API 요청을 차단하여, 애플리케이션에 대한 부담을 줄이는 역할을 한다. 반면 livenessProbe는 재시작을 트리거하기 때문에, readinessProbe와는 다른 주기로 설정하여 Pod가 너무 쉽게 재기동되지 않도록 해야 한다.
즉, 일시적 장애라면 readinessProbe로 외부 요청을 차단해 회복 시간을 확보하고, livenessProbe는 일정 시간 동안 관찰한 후에도 복구되지 않을 때만 재시작을 유도하는 식으로 설정하는 것이 좋다.
실습 미션
응용 과제
(참고)실습 환경 구성 - 큐브옵스 커뮤니티
1. startupProbe가 실패 되도록 설정해서 Pod가 무한 재기동 상태가 되도록 설정해 보세요.
Hint: startupProbe에 failureThreshold(몇 번 연속으로 실패해야 실패로 간주할지를 설정하는 값) 수치를 App이 기동안되도록 낮추면 됩니다.
1. deployment startupProbe.failureThreshold 속성 1로 수정
# kubectl edit deploy -n <namespace> <deployment name>
kubectl edit deploy -n anotherclass-123 api-tester-1231
...
startupProbe:
httpGet:
path: "/startup"
port: 8080
periodSeconds: 5
failureThreshold: 1 # 수정
readinessProbe:
httpGet:
path: "/readiness"
port: 8080
periodSeconds: 10
failureThreshold: 3
livenessProbe:
httpGet:
path: "/liveness"
port: 8080
periodSeconds: 10
failureThreshold: 3
...
2. 확인
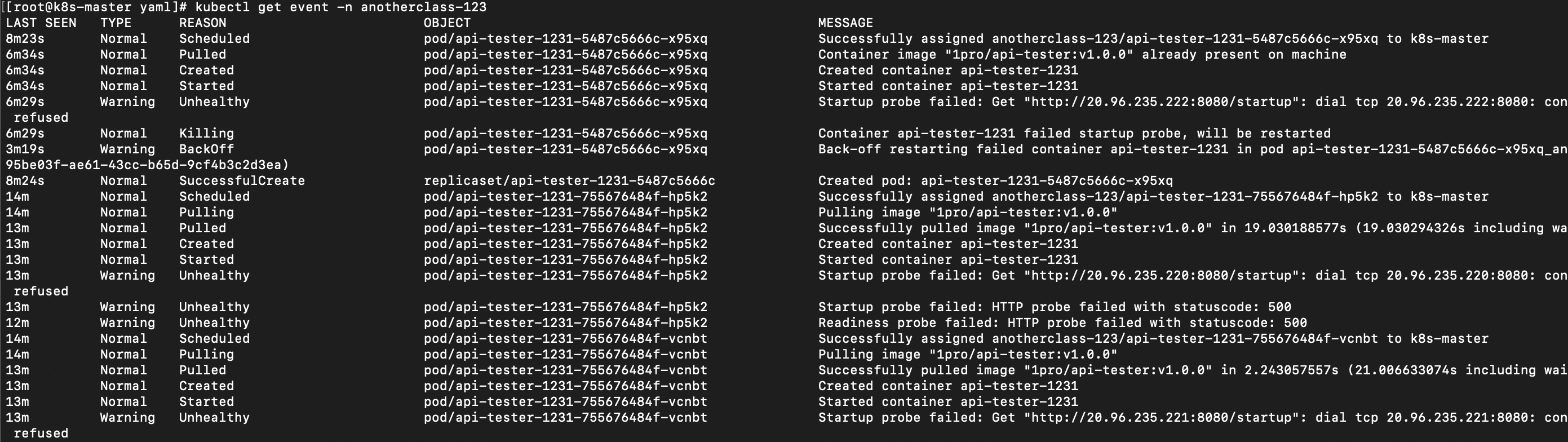
이벤트 로그를 살펴보면 Pod 생성 및 컨테이너 시작 → Startup Probe 실패 → 컨테이너 종료 및 재시작 패턴이 반복되고 있음을 확인할 수 있다.
# kubectl get event -n <namespace>
kubectl get event -n anotherclass-123 --watch
2. 일시적 장애 상황(App 내부 부하 증가)가 시작 된 후, 30초 뒤에 트래픽이 중단되고, 3분 뒤에는 App이 재기동 되도록 설정해 보세요.
Hint: livenessProbe의 periodSeconds(Probe를 얼마나 자주 실행할지 결정)나 failureThreshold를 늘리면 됩니다.
(아래 API를 날리면 readinessProbe와 livenessProbe가 동시에 실패하게 됩니다)
// 부하 증가 API - (App 내부 isAppReady와 isAppLive를 False로 바꿈) curl http://192.168.56.30:31231/server-load-on // 외부 API 실패 curl http://192.168.56.30:31231/hello // 부하 감소 API - (App 내부 isAppReady와 isAppLive를 True로 바꿈) curl http://192.168.56.30:31231/server-load-off
1. deployment livenessProbe.periodSeconds 속성 수정
# kubectl edit deploy -n <namespace> <deployment name>
kubectl edit deploy -n anotherclass-123 api-tester-1231
...
startupProbe:
httpGet:
path: "/startup"
port: 8080
periodSeconds: 5
failureThreshold: 10
readinessProbe:
httpGet:
path: "/readiness"
port: 8080
periodSeconds: 10 # 10초마다 Probe 실행
failureThreshold: 3 # 3번 연속 실패 시 트래픽 중단 (10초*3 = 30초)
livenessProbe:
httpGet:
path: "/liveness"
port: 8080
periodSeconds: 60 # 60초마다 Probe 실행
failureThreshold: 3 # 3번 연속 실패 시 pod 재기동 (60초*3 = 180초)
...
2. 확인
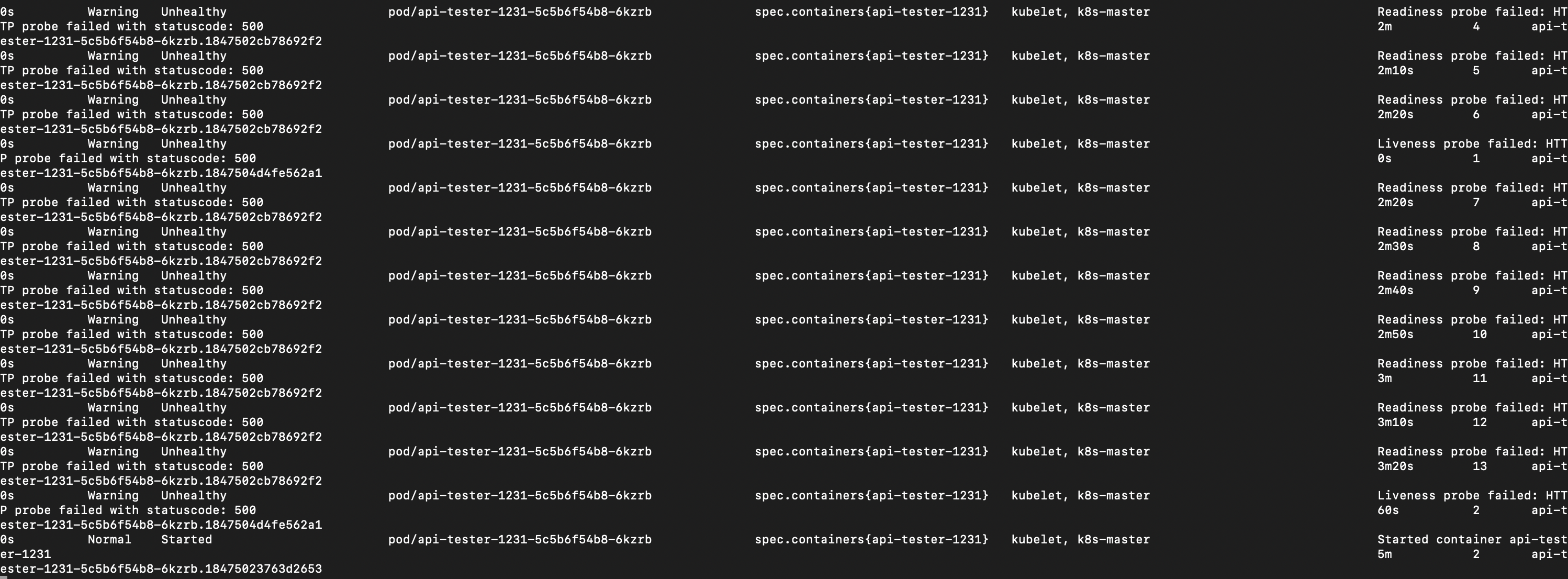
이벤트 로그를 살펴보면 readiness실패 시작 후 10초 간격으로 요청, Liveness 실패 시작 후 60초 간격으로 요청 3번째 실패 시점에 컨테이너가 재기동됨을 확인할 수 있다.
# kubectl get event -n <namespace>
kubectl get event -n anotherclass-123 --watch -o wide
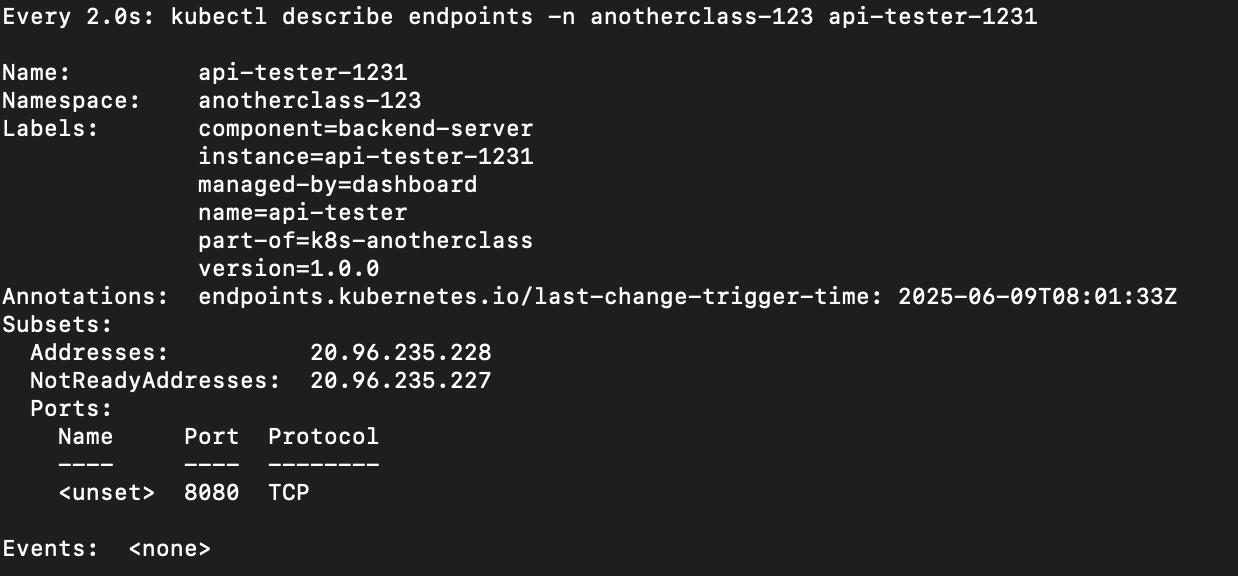
endpoint를 지속적으로 확인해보면 Readiness Probe에 의해 실시간으로 제외되는 것을 확인할 수 있다.
# kubectl describe endpoints -n <namespace> <service name>
watch kubectl describe endpoints -n anotherclass-123 api-tester-1231
3. Secret 파일(/usr/src/myapp/datasource/postgresql-info.yaml)이 존재하는지 체크하는 readinessProbe를 만들어 보세요.
Hint: readinessProbe에는 exec라는 속성으로 command를 Pod에 날릴 수 있고, 이는 App기동시 꼭 필요한 파일이 있는지를 체크합니다.
1. deployment readinessProbe 속성 수정
# kubectl edit deploy -n <namespace> <deployment name>
kubectl edit deploy -n anotherclass-123 api-tester-1231
...
startupProbe:
httpGet:
path: "/startup"
port: 8080
periodSeconds: 5
failureThreshold: 10
readinessProbe:
exec: # httpGet 속성 삭제 후 추가
command: ["cat", "/usr/src/myapp/datasource/postgresql-info.yaml"]
periodSeconds: 10
failureThreshold: 3
livenessProbe:
httpGet:
path: "/liveness"
port: 8080
periodSeconds: 10
failureThreshold: 3
...
2. 확인
컨테이너 내부에 유효하지 않은 파일을 체크하도록 설정한 경우 다음과 같은 이벤트 확인이 가능하다.

# kubectl get event -n <namespace>
kubectl get event -n anotherclass-123 --watch
Configmap, Secret
Kubernetes에서 ConfigMap과 Secret을 사용하면 앱 외부의 설정 데이터를 주입할 수 있다.
ConfigMap 데이터
ConfigMap은 다음과 같은 데이터를 담는 데 사용된다.
- 인프라 환경에 따른 설정 값 (예: 환경 이름, 엔드포인트)
- 앱의 기능을 제어하기 위한 플래그나 옵션
- 외부 시스템에서 주입되는 설정 값
기존에는 이런 데이터들을 운영자가 직접 설정 파일이나 코드 내부에 관리했지만, Kubernetes에서는 ConfigMap으로 외부화하면서 설정을 보다 체계적으로 관리할 수 있게 되었다.
Secret의 용도
Secret은 민감한 데이터를 다루기 위해 만들어졌으며 다음과 같은 특징이 있다.
- 값은 모두 Base64로 인코딩되어 저장됨 (암호화가 아님)
- 환경변수로 넣을 수도 있지만, 보안상 노출 우려가 있어 volume 마운트 방식으로 많이 사용됨
- type 필드를 통해 다양한 목적에 맞게 활용 가능
- Opaque: 기본적인 비밀 데이터 저장
- kubernetes.io/dockerconfigjson: 프라이빗 레지스트리 인증 정보 저장
- kubernetes.io/tls: TLS 인증서 저장
Secret은 강력한 보안 수단은 아니다. 따라서 민감 데이터는 파이프라인에 직접 포함시키기보다는 클러스터 내부에서 직접 생성하고 관리하는 것이 권장된다.
Secret을 꼭 써야 할까?
비밀 데이터를 저장한다고 해서 무조건 Secret을 써야 하는 건 아니다.
- 이미 암호화된 데이터를 사용하는 경우: 굳이 Secret을 쓰기보다는 ConfigMap에 넣어도 무방
- 외부 시스템(Vault 등)과 연동하는 경우: 앱 기동 시 직접 외부 시스템에 요청해서 데이터를 받아오는 방식도 고려해볼 수 있음
환경변수 vs Volume 마운트
설정 값을 앱에 주입할 때 환경변수와 volume 마운트 방식의 차이는 다음과 같다.
- 환경변수: 앱이 기동 시점에만 값을 읽기 때문에, 이후 값이 변경되어도 반영되지 않음
- Volume 마운트: 앱이 마운트된 파일을 주기적으로 확인하면 실시간 변경 감지 가능
실습 미션
응용 과제
1. Configmap의 환경변수들을 Secret을 사용해서 작성하고, App에서는 같은 결과가 나오도록 확인해 보세요.
1.Secret 생성
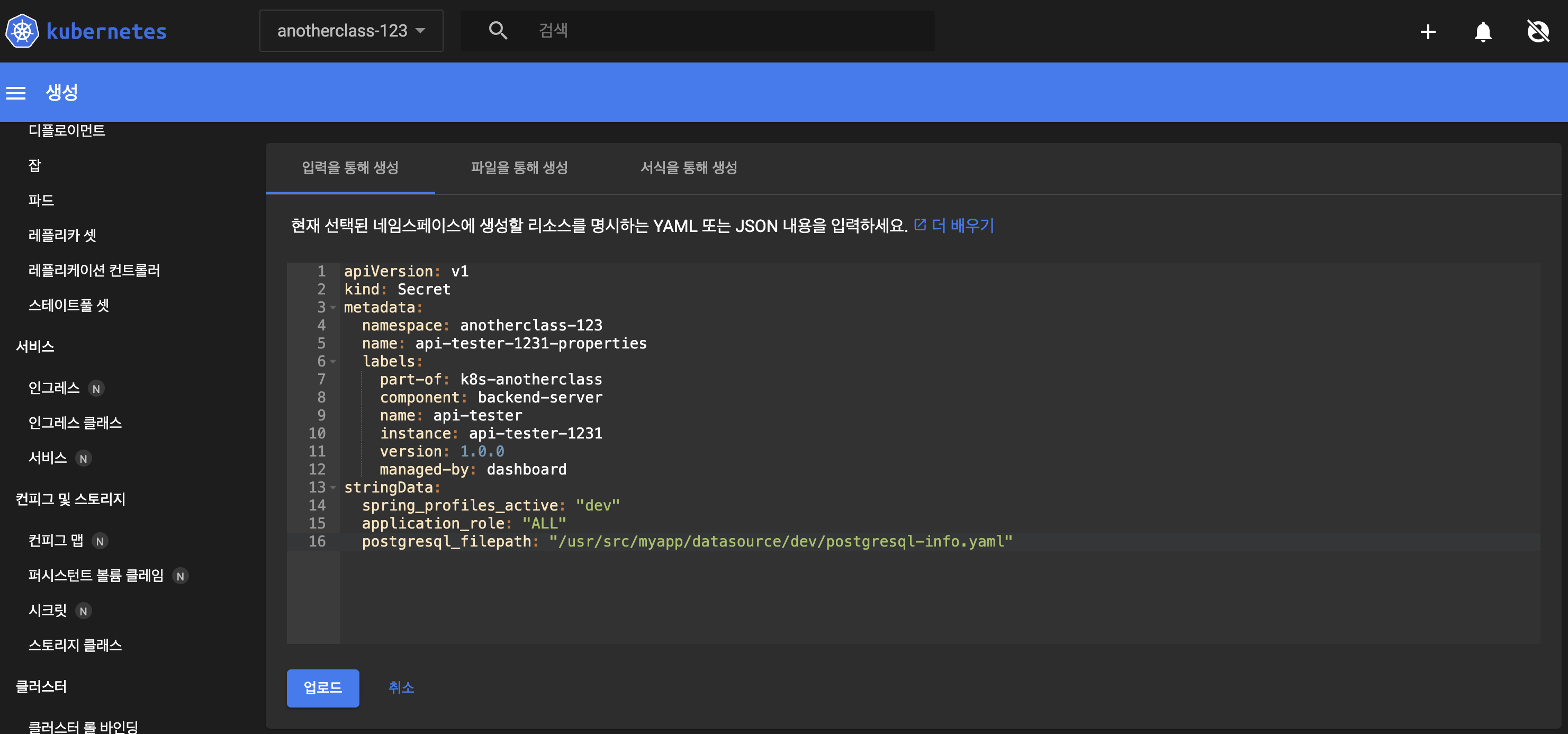
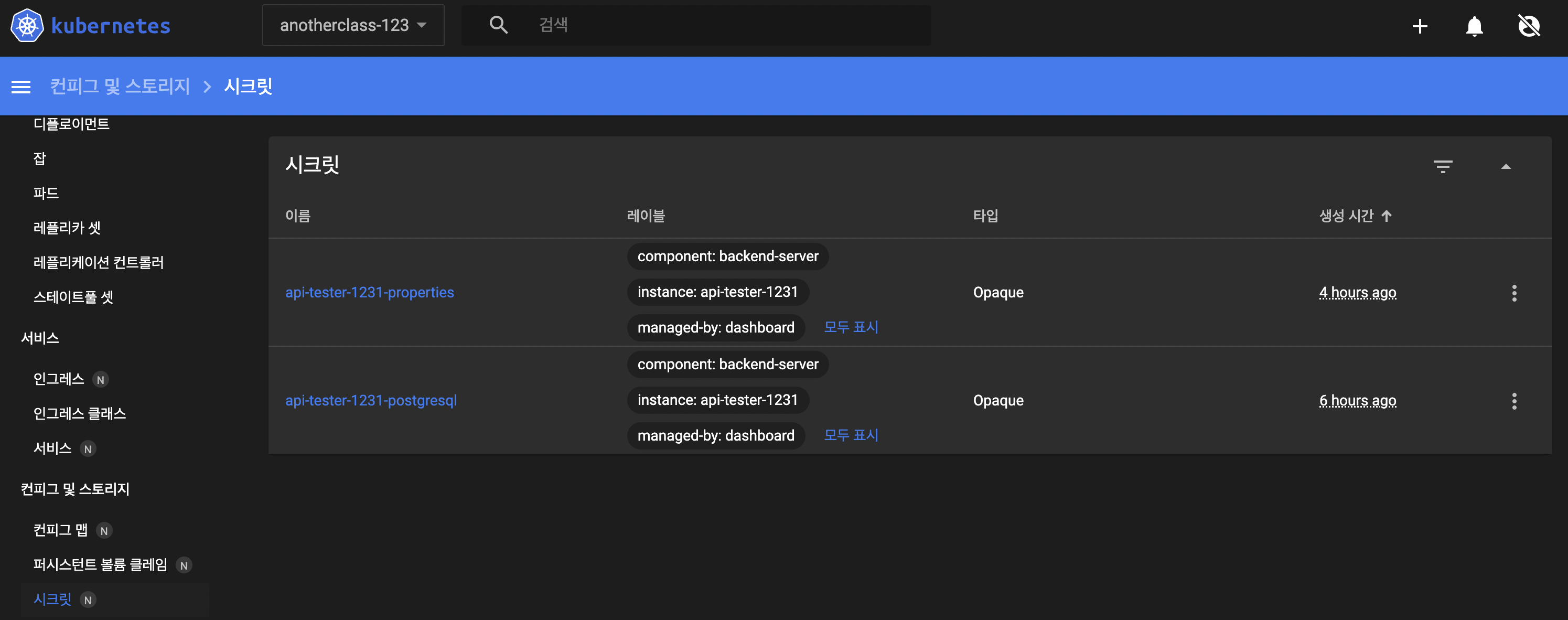
- kubernetes dashboard에서 생성: kubernetes dashboard 접속 후 우측 상단 + 아이콘 클릭 → secret 내용 입력 후 업로드 버튼 클릭 → 생성 확인
apiVersion: v1
kind: Secret
metadata:
namespace: anotherclass-123
name: api-tester-1231-properties
labels:
part-of: k8s-anotherclass
component: backend-server
name: api-tester
instance: api-tester-1231
version: 1.0.0
managed-by: dashboard
stringData:
spring_profiles_active: "dev"
application_role: "ALL"
postgresql_filepath: "/usr/src/myapp/datasource/dev/postgresql-info.yaml"
- kubectl 커맨드로 생성
# 방법 1
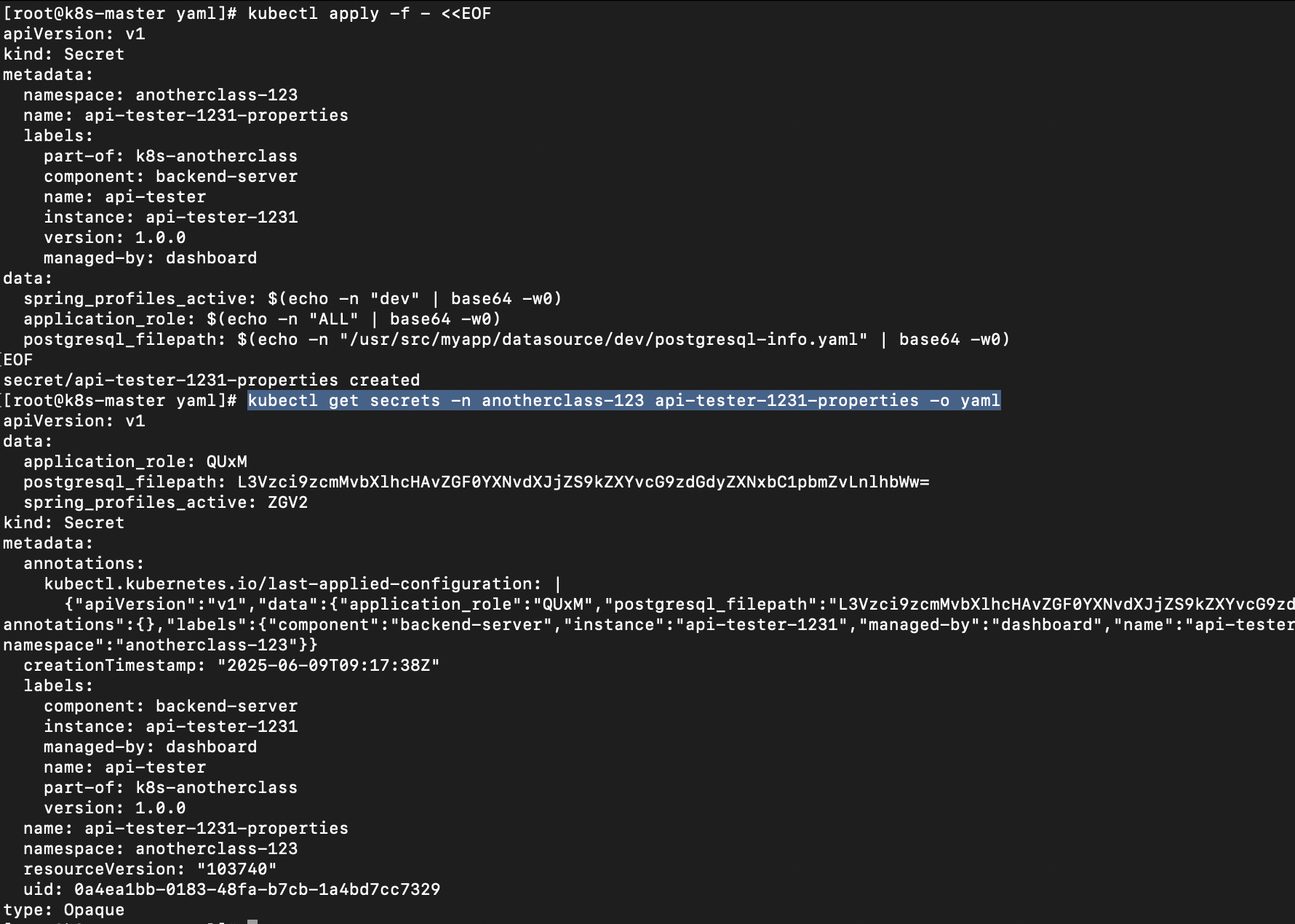
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
namespace: anotherclass-123
name: api-tester-1231-properties
labels:
part-of: k8s-anotherclass
component: backend-server
name: api-tester
instance: api-tester-1231
version: 1.0.0
managed-by: dashboard
data:
spring_profiles_active: $(echo -n "dev" | base64 -w0)
application_role: $(echo -n "ALL" | base64 -w0)
postgresql_filepath: $(echo -n "/usr/src/myapp/datasource/dev/postgresql-info.yaml" | base64 -w0)
EOF
# 확인
kubectl get secrets -n anotherclass-123 api-tester-1231-properties -o yaml
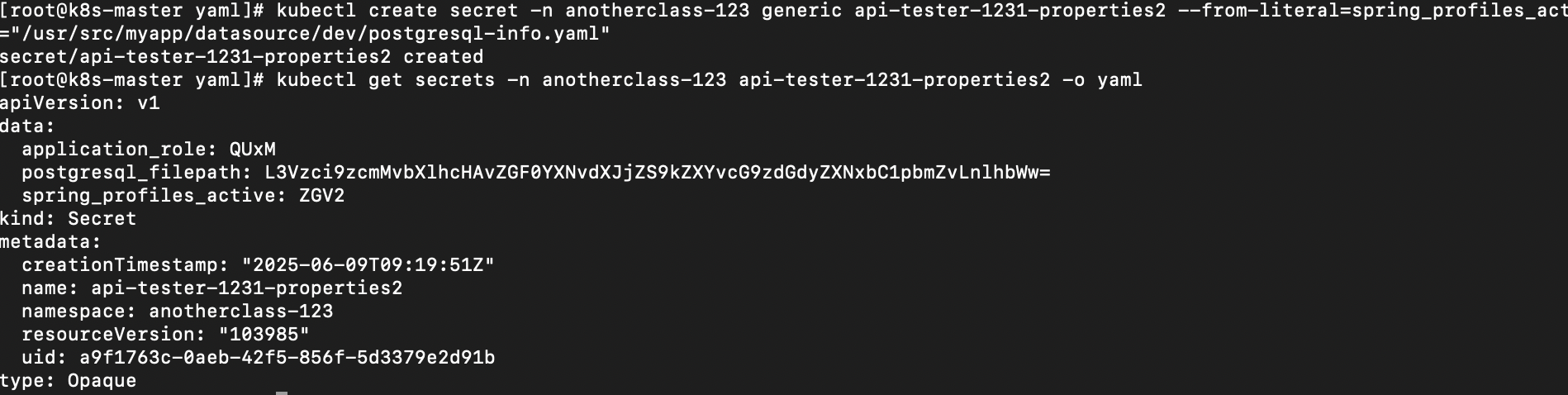
# 방법 2
kubectl create secret -n anotherclass-123 generic api-tester-1231-properties2 --from-literal=spring_profiles_active=dev --from-literal=application_role=ALL --from-literal=postgresql_filepath="/usr/src/myapp/datasource/dev/postgresql-info.yaml"
# 확인
# kubectl get secrets -n <namespace> <secret name> -o yaml
kubectl get secrets -n anotherclass-123 api-tester-1231-properties2 -o yaml
2. 적용
- deployment envFrom 수정
# kubectl edit -n <namespace> deployments.apps <deployment name>
kubectl edit -n anotherclass-123 deployments.apps api-tester-1231
...
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: k8s-master
containers:
- name: api-tester-1231
image: 1pro/api-tester:v1.0.0
envFrom:
- secretRef: # configmap 대신 secret 연결
name: api-tester-1231-properties
...
3. 확인
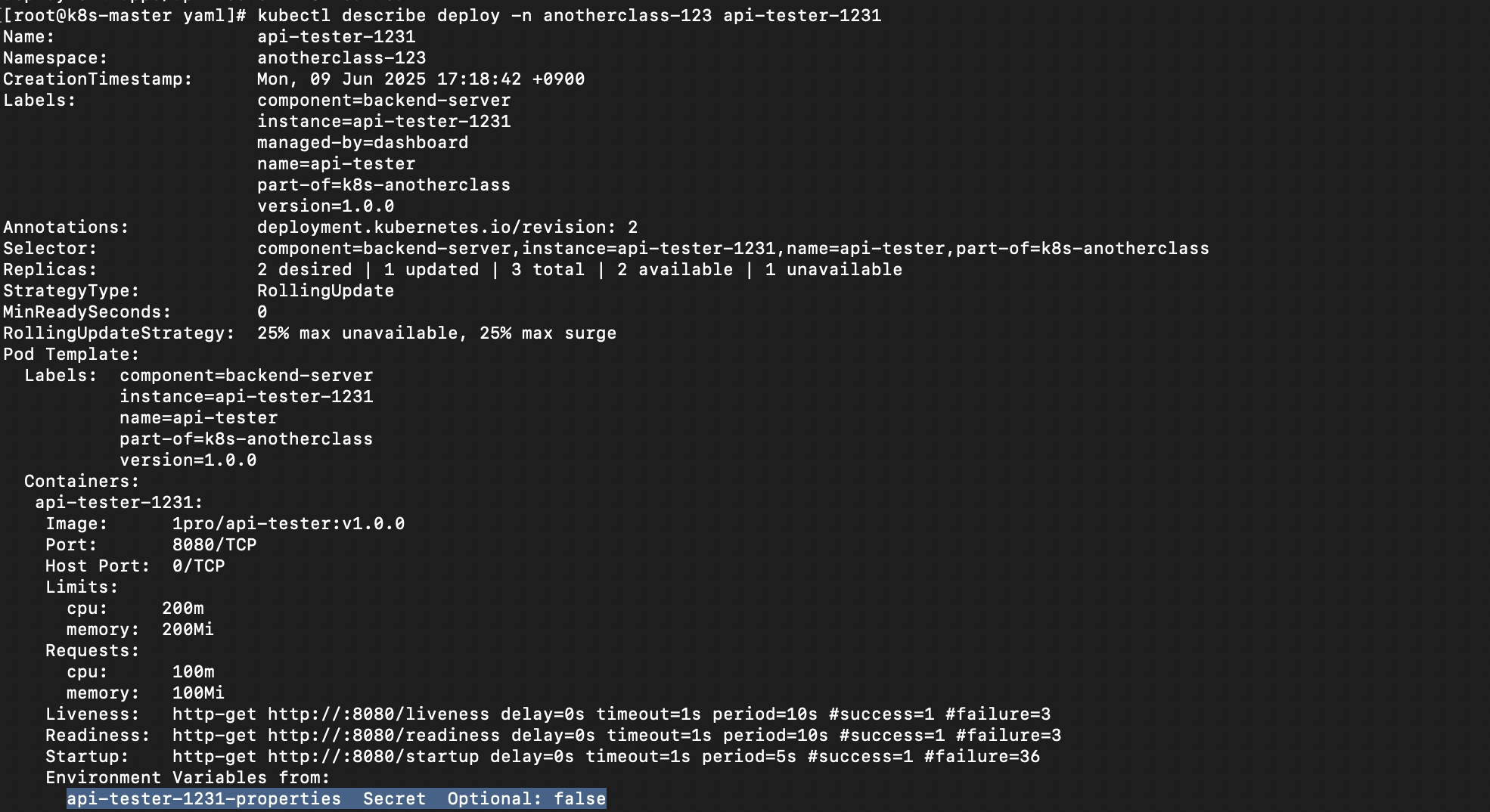
# kubectl describe deploy -n <namespace> <deployment name>
kubectl describe deploy -n anotherclass-123 api-tester-1231
2. 반대로 Secret의 DB정보를 Configmap으로 만들어보고 App을 동작시켜 보세요.
1. Configmap 생성
apiVersion: v1
kind: ConfigMap
metadata:
namespace: anotherclass-123
name: api-tester-1231-postgresql
labels:
part-of: k8s-anotherclass
component: backend-server
name: api-tester
instance: api-tester-1231
version: 1.0.0
managed-by: dashboard
data:
postgresql-info.yaml: |
driver-class-name: "org.postgresql.Driver"
url: "jdbc:postgresql://postgresql:5431"
username: "dev"
password: "dev123"
kubectl create -f api-tester-postgresql-cm.yaml
2. 적용
- deployment volumeMounts.name과 volumes 수정
# kubectl edit -n <namespace> deployments.apps <deployment name>
kubectl edit -n anotherclass-123 deployments.apps api-tester-1231
...
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: k8s-master
containers:
- name: api-tester-1231
image: 1pro/api-tester:v1.0.0
volumeMounts: # 수정
- name: configmap-datasource
mountPath: /usr/src/myapp/datasource/dev
volumes: # 수정
- name: configmap-datasource
configMap:
name: api-tester-1231-postgresql
...
3. 확인
# kubectl describe deploy -n <namespace> <deployment name>
kubectl describe deploy -n anotherclass-123 api-tester-1231

PV/PVC (Persistent Volume/Persistent Volume Claim)
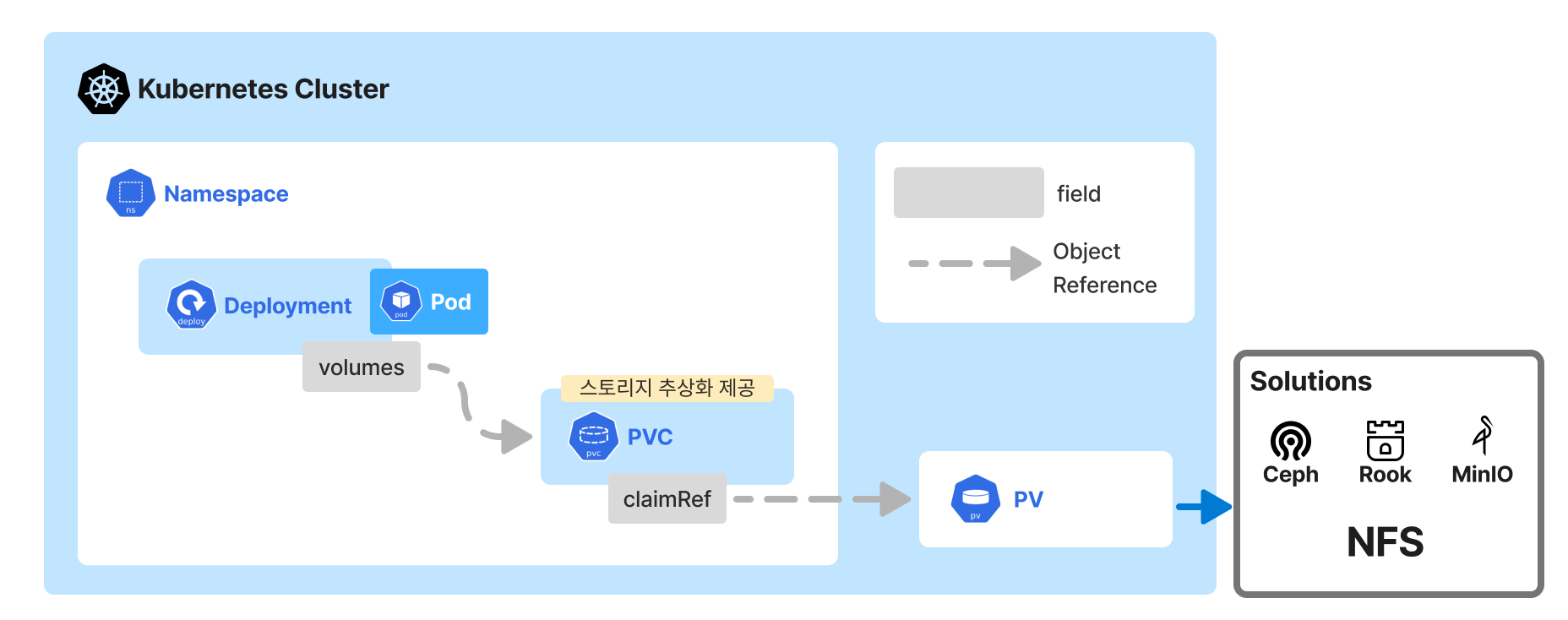
PV/PVC의 필요성
PV와 PVC를 사용하는 이유는 Pod가 종료될 때 파일이 삭제되는 것을 방지하고 데이터를 지속적으로 보존하기 위함이다. 이를 통해 Pod가 재기동 되어도 기존 데이터를 유지할 수 있다.
테스트 환경 활용
PV의 local 속성을 사용하면 노드의 로컬 스토리지를 직접 활용할 수 있다. 이때 반드시 nodeAffinity 설정을 통해 Pod가 생성될 특정 노드를 지정해야 한다. 별도의 스토리지를 구축하기 어려운 테스트 환경에서 노드 스토리지를 임시로 사용하는 데 적합하다.
hostPath 사용의 한계
간단한 설정을 원할 경우 hostPath와 nodeSelector를 사용하기도 하지만, 보안상 권장하지 않는다. hostPath는 노드 내부 정보를 제한적으로 읽는 용도로만 사용하며, 디렉터리를 지정하고 ReadOnly로 마운트하는 것이 좋다.
운영 환경 권고 사항
실제 운영 환경에서는 NAS나 다양한 볼륨 솔루션과 연결하여 자동화된 운영을 권장한다. PV/PVC를 활용하면 개발자는 PVC라는 인터페이스를 통해 손쉽게 스토리지 자원을 요청할 수 있으며, 이로 인해 PV의 변경이 Pod에 미치는 영향을 최소화할 수 있다.
실습 미션
응용 과제
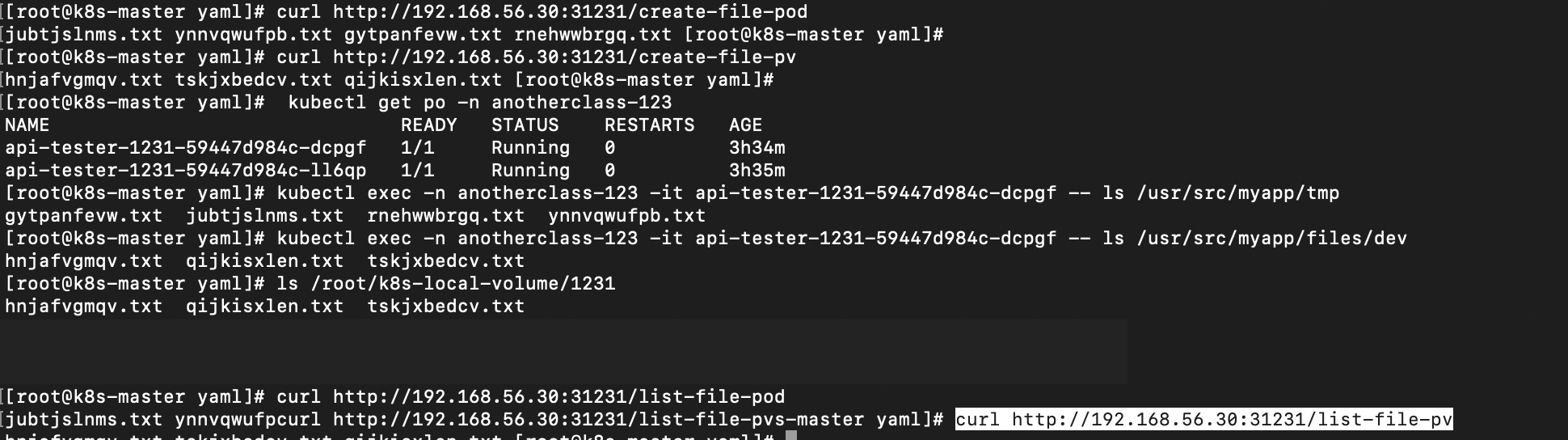
1. local 동작 확인
# 파일 생성
curl http://192.168.56.30:31231/create-file-pod
curl http://192.168.56.30:31231/create-file-pv
# pod 이름 확인
kubectl get po -n anotherclass-123
# 2번 - Container 임시 폴더 확인
## kubectl exec -n anotherclass-123 -it <pod-name> -- ls /usr/src/myapp/tmp
kubectl exec -n anotherclass-123 -it api-tester-1231-59447d984c-dcpgf -- ls /usr/src/myapp/tmp
# 2번 - Container 영구저장 폴더 확인
## kubectl exec -n anotherclass-123 -it <pod-name> -- ls /usr/src/myapp/files/dev
kubectl exec -n anotherclass-123 -it api-tester-1231-59447d984c-dcpgf -- ls /usr/src/myapp/files/dev
# 2번 - master node 폴더 확인
ls /root/k8s-local-volume/1231
# 3번 - Pod 삭제
kubectl delete -n anotherclass-123 pod <pod-name>
# 4번 API - 파일 조회
curl http://192.168.56.30:31231/list-file-pod
curl http://192.168.56.30:31231/list-file-pv
2. hostPath 동작 확인
# persistentVolumeClaim 삭제 후 hostPath로 수정
kubectl edit -n anotherclass-123 deployments.apps api-tester-1231
## deployment yaml
...
volumes:
- name: files
hostPath:
path: /root/k8s-local-volume/1231
...
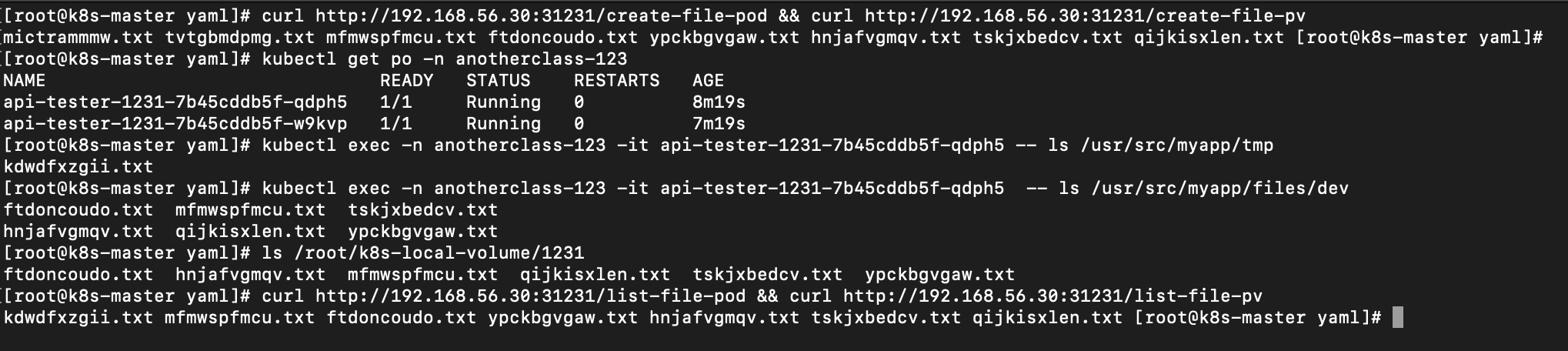
# 파일 생성
curl http://192.168.56.30:31231/create-file-pod
curl http://192.168.56.30:31231/create-file-pv
# pod 이름 확인
kubectl get po -n anotherclass-123
# 2번 - Container 임시 폴더 확인
## kubectl exec -n anotherclass-123 -it <pod-name> -- ls /usr/src/myapp/tmp
kubectl exec -n anotherclass-123 -it api-tester-1231-7b45cddb5f-qdph5 -- ls /usr/src/myapp/tmp
# 2번 - Container 영구저장 폴더 확인
## kubectl exec -n anotherclass-123 -it <pod-name> -- ls /usr/src/myapp/files/dev
kubectl exec -n anotherclass-123 -it api-tester-1231-7b45cddb5f-qdph5 -- ls /usr/src/myapp/files/dev
# 2번 - master node 폴더 확인
ls /root/k8s-local-volume/1231
# 3번 - Pod 삭제
kubectl delete -n anotherclass-123 pod <pod-name>
# 4번 API - 파일 조회
curl http://192.168.56.30:31231/list-file-pod
curl http://192.168.56.30:31231/list-file-pv
Deployment
업데이트 전략(Strategy)
Deployment의 업데이트 방식은 strategy의 타입에 따라 달라진다.
- Recreate: 기존 Pod를 모두 삭제하고 새로운 Pod를 생성, 이 과정에서 서비스 중단 발생
- RollingUpdate: 서비스 중단 없이 새 Pod가 기동된 후 기존 Pod를 삭제, 일시적으로 자원 사용량이 증가하며 두 버전이 동시에 존재할 수 있음
- Blue/Green: 별도 배포 솔루션을 통해 두 버전을 독립적으로 관리, 두 버전이 동시에 호출되지 않지만 자원 사용량이 더 큼
RollingUpdate 주요 옵션
- maxUnavailable: 업데이트 중 유지할 최소 Pod 수
- maxSurge: 추가로 생성할 최대 Pod 수
두 값을 100%로 설정하면 Recreate 방식과 같다. 서비스 안정성을 위해선 보통 maxUnavailable을 0%, maxSurge를 100%로 설정해 Pod 개수를 유지한다.
실습 미션
응용 과제
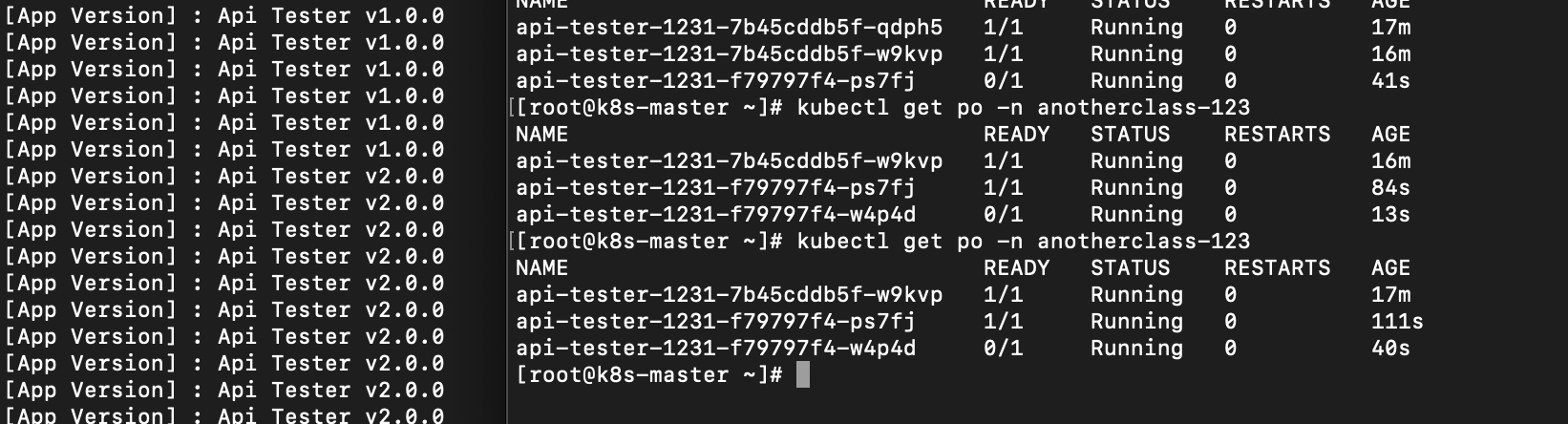
1. RollingUpdate
롤링 업데이트 과정에서는 v1과 v2가 동시에 존재하며, 트래픽이 두 버전으로 분산되어 사용자 요청이 번갈아 전달된다.
# HPA minReplica 2로 변경
kubectl patch -n anotherclass-123 hpa api-tester-1231-default -p '{"spec":{"minReplicas":2}}'
# 그외 Deployment scale 명령
kubectl scale -n anotherclass-123 deployment api-tester-1231 --replicas=2
## edit로 모드로 직접 수정
kubectl edit -n anotherclass-123 deployment api-tester-1231
## 지속적으로 Version호출 하기 (업데이트 동안 리턴값 관찰)
while true; do curl http://192.168.56.30:31231/version; sleep 2; echo ''; done;
## 별도의 원격 콘솔창을 열어서 업데이트 실행
kubectl set image -n anotherclass-123 deployment/api-tester-1231 api-tester-1231=1pro/api-tester:v2.0.0
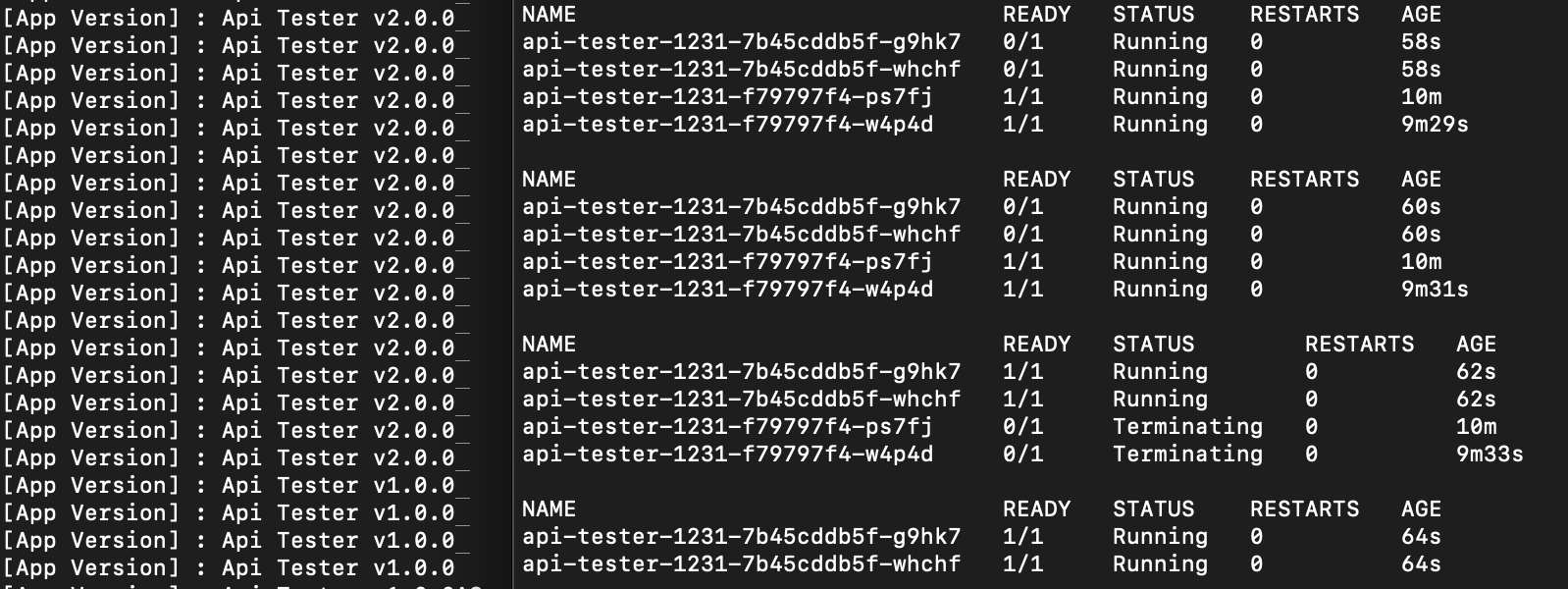
2. RollingUpdate (maxUnavailable: 0%, maxSurge: 100%)
maxUnavailable: 0%, maxSurge: 100% 설정은 기존 Pod을 모두 유지한 채 새 버전을 최대 수만큼 추가로 생성하여 무중단 배포를 가능하게 한다.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0% # 수정
maxSurge: 100% # 수정
kubectl set image -n anotherclass-123 deployment/api-tester-1231 api-tester-1231=1pro/api-tester:v1.0.0
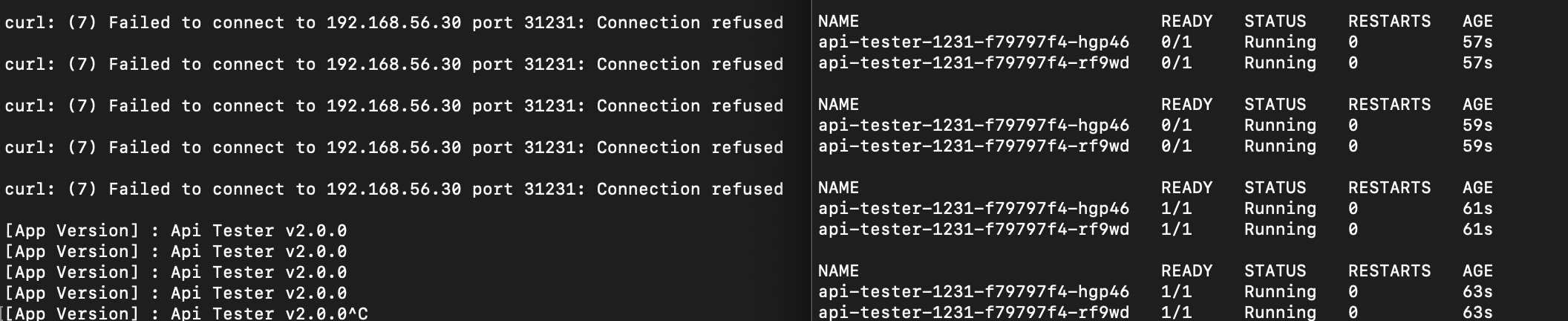
3. Recreate
Recreate 전략은 기존 Pod을 모두 종료한 뒤 새 버전을 생성하므로, 배포 중 일시적으로 서비스가 중단될 수 있다.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
replicas: 2
strategy:
type: Recreate # 수정
rollingUpdate: # 삭제
maxUnavailable: 0% # 삭제
maxSurge: 100% # 삭제
kubectl set image -n anotherclass-123 deployment/api-tester-1231 api-tester-1231=1pro/api-tester:v2.0.0
4. Rollback
kubectl rollout undo -n anotherclass-123 deployment/api-tester-1231
Service
Service의 역할
Service는 외부 트래픽을 Pod로 연결하며, 내부 DNS를 통해 서비스 이름으로 API 호출이 가능한 서비스 디스커버리 역할을 수행한다. Kubernetes는 Pod의 생성 및 삭제에 따라 Service에 등록된 IP를 자동으로 관리하며, 로드밸런싱을 수행한다.
ContainerPort 활용
Pod의 containerPort 속성은 정보성 속성으로, 이 이름을 Service의 targetPort로 설정하면 Pod의 Port 변경 시 Service가 자동으로 대응한다.
# deployment yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- name: http # 해당 속성을 targetPort로 설정
containerPort: 8080 # 나중에 바뀔 수 있음
# service yaml
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
selector:
app: my-app
ports:
- name: http
port: 80
targetPort: http # 이름을 기준으로 연결
실습 미션
응용 과제
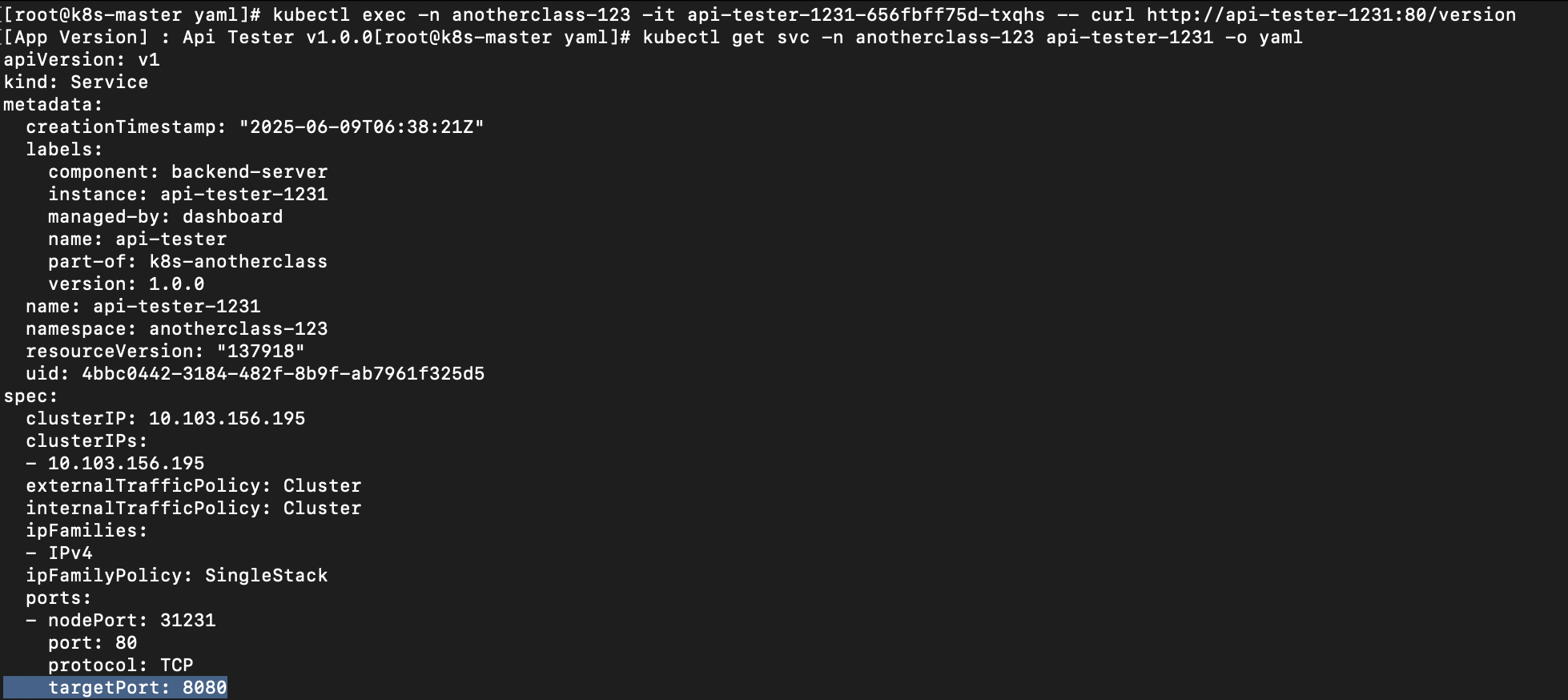
1. Pod 내부에서 Service 명으로 API 호출 [서비스 디스커버리]
# Version API 호출
## kubectl exec -n anotherclass-123 -it <pod name> -- curl http://api-tester-1231:80/version
kubectl exec -n anotherclass-123 -it api-tester-1231-755676484f-5zp62 -- curl http://api-tester-1231:80/version
2. Deployment에서 Pod의 ports 전체 삭제, Service targetPort를 http -> 8080으로 수정
# deployment yaml
...
containers:
- name: api-tester-1231
ports: # 삭제
- name: http # 삭제
containerPort: 8080 # 삭제
...
# service yaml
...
spec:
ports:
- port: 80
targetPort: 8080 # 변경
nodePort: 31231
...
3. 다시 Pod 내부에서 Service 명으로 API 호출 [서비스 디스커버리]
# pod 내부에서 Version API 호출
## kubectl exec -n anotherclass-123 -it <pod name> -- curl http://api-tester-1231:80/version
kubectl exec -n anotherclass-123 -it api-tester-1231-656fbff75d-txqhs -- curl http://api-tester-1231:80/version
HPA
HPA 개념 및 계산 방법
HPA의 평균 CPU 사용률(averageUtilization) 계산 공식은 다음과 같다.
# 계산 결과 소수점은 올림 처리된다.
현재 Pod 수 × (현재 평균 CPU 사용량 / HPA 기준 CPU 사용량) = 조정될 Pod 수
메모리와 CPU 활용 기준
메모리는 증가한 뒤 다시 줄어들지 않고 유지되는 특성이 있어, HPA에서는 CPU를 주로 사용한다. 하지만 CPU만으로 모든 부하를 정확히 판단하기 어려워, 다양한 부하 지표를 제공하는 솔루션과 연동하는 것이 권장된다.
스케일링 한계와 behavior 옵션
자동화된 스케일링은 보조적 수단이며, 급격한 트래픽 상황에서는 Pod 재기동 및 셀프힐링 중 일시적 서비스 중단이 발생할 수 있다. 이를 방지하기 위해 HPA의 behavior 옵션을 활용한다.
- scaleUp: 일정 시간 동안 임계치를 초과하면 Pod 추가
- scaleDown: 부하가 감소해도 일정 시간 동안 Pod 수 유지
- policies: 한 번에 제거할 Pod 수 제한
리소스가 증가하는 것을 의미할 때 Kubernetes에서는 scaleUp이라는 표현을 사용한다.
자동 스케일링 현실적 한계
자동 스케일링을 사용하더라도 급격한 트래픽 증가 시 기존 Pod가 중단되고 새로운 Pod가 추가되는 과정에서 서비스 중단이 발생할 수 있다. 이를 방지하려면 미리 충분한 여유 자원을 확보하고 트래픽 관리를 병행해야 한다.
HPA 설정 시 고려사항
- 부하 지표를 정확히 파악하고, 적절한 임계치를 설정
- 잦은 스케일링을 방지하기 위해 behavior 옵션 활용
- 애플리케이션 특성에 맞는 커스텀 메트릭을 사용하여 더욱 정교한 스케일링 수행
실습 미션
응용 과제
(참고)실습 환경 구성 - 큐브옵스 커뮤니티
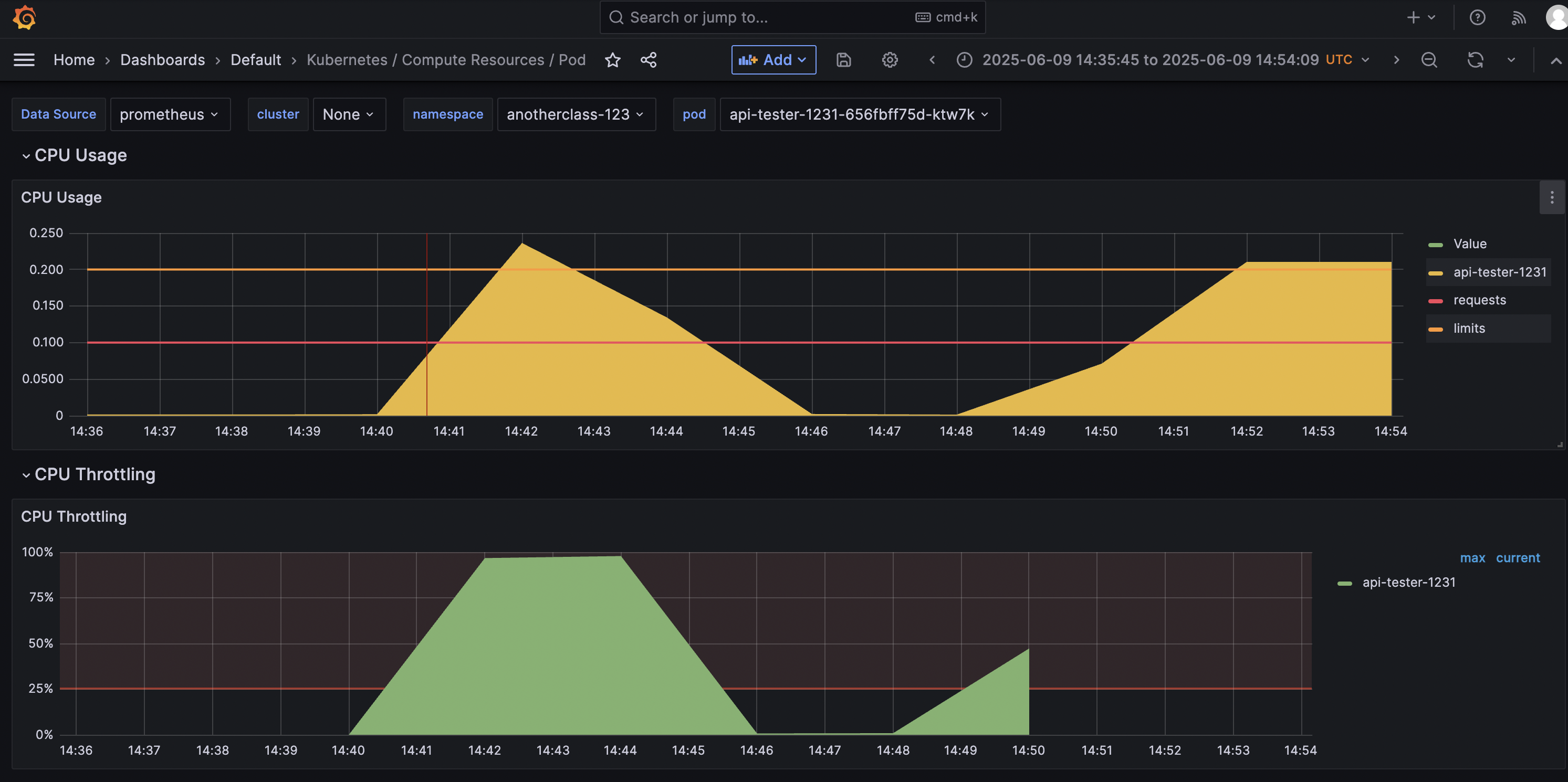
1. 부하 발생
http://192.168.56.30:31231/cpu-load?min=3 # 3분 동안 부하 발생
2. 부하 확인
kubectl top -n anotherclass-123 pods
kubectl get hpa -n anotherclass-123
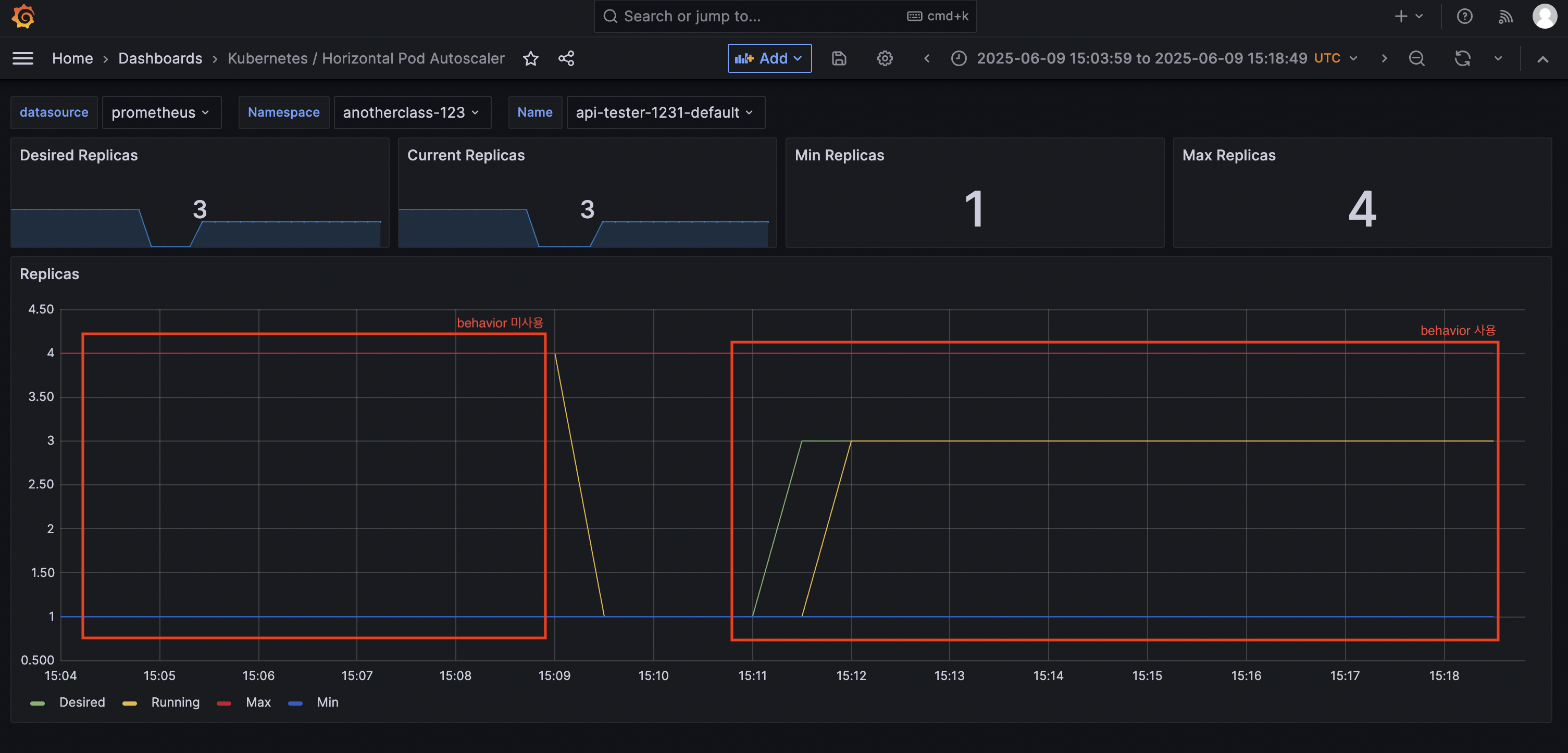
3. [behavior] 미사용으로 적용
kubectl edit -n anotherclass-123 hpa api-tester-1231-default
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
namespace: anotherclass-123
name: api-tester-1231-default
spec:
behavior: # 삭제
scaleUp: # 삭제
stabilizationWindowSeconds: 120 # 삭제
4. 부하 발생
http://192.168.56.30:31231/cpu-load?min=3 # 3분 동안 부하 발생
5. 부하 확인
kubectl top -n anotherclass-123 pods
kubectl get hpa -n anotherclass-123
회고
이번주 강의를 통해 쿠버네티스가 단순히 컨테이너를 띄우고 관리하는 도구가 아니라 서비스 안정성을 위해 얼마나 정교하게 설계된 시스템인지 깨달았다. 특히 각 오브젝트들이 단순히 역할만 나누어진게 아니라, 운영 자동화를 위해 유기적으로 연결되어 있다는 점이 인상 깊었다.
그동안 쿠버네티스 오브젝트들의 개념은 알고 있었지만, 비슷한 기능을 수행하는 경우 정확히 어떤 차이가 있는지 자세히 알지 못했다. 이번 강의에서는 그 작은 차이와 실제 운영에서 자주 쓰이는 사례들을 볼 수 있어서 추상적인 개념이 아닌 구체적인 운영 시나리오 속에서 오브젝트들을 이해할 수 있었다.
단순히 기능을 아는 것이 아니라 “왜 이 기능이 필요한가”, 그리고 “어떤 상황에서 어떻게 써야 하는가”에 대한 감각이 생겼다는 점이다. 단순히 쿠버네티스를 쓰는 사람이 아니라, 쿠버네티스를 “잘” 쓰는 사람이 되기 위한 시작점에 서 있는 느낌이다. 앞으로는 단순히 YAML을 작성하는 게 아니라, 그 안에 담긴 의도와 운영 흐름까지 함께 고민하는 엔지니어가 되고 싶다.

뻐꾸기 (Common Cuckoo)
Cuculus canorus
뻐꾸기과에 속하는 철새로, 뚜렷한 ‘뻐꾹’ 소리로 잘 알려져 있다. 몸은 회색빛을 띠며, 배에는 가로줄 무늬가 있다. 다른 새의 둥지에 알을 낳는 탁란 습성으로도 유명하다.