
다양한 재시도(Retry) 전략 구현 및 요청 분산 비교
재시도 방식에 따른 요청 분산 비교 실험
Prologue: 재시도 전략, 실험으로 이해하기
개발 관련 글들을 읽다 보면, 문제를 해결하기 위해 다양한 방식이 제안되는 걸 자주 보게 된다. 그중에는 “이게 왜 더 좋은 방법일까?”라는 의문이 드는 것도 있고, 말로는 이해되지만 체감되지 않는 것도 있다.
그래서 직접 구현하고, 관찰하고, 정리해보기로 했다. 단순히 읽는 것을 넘어서, 실제로 해보며 체득하는 것이 목표이다.
첫번째 실험은 Good Retry, Bad Retry: An Incident Story 글을 참고하여 다양한 재시도 방식을 구현해보고, 그 차이를 눈으로 확인해보기로 했다.
실험 목적
- 동일한 요청 실패 시, 서로 다른 재시도 전략을 적용했을 때 시스템 부하 양상이 어떻게 달라지는지를 실험
- 특히 “짧은 시간 동안 얼마나 많은 요청이 집중되는가?”에 주목하여 분석
실험 조건
- 요청 수: 100개
- 요청 성공 확률: 약 70%
- 최대 재시도 횟수: 3회
- 시간 단위: 밀리초(ms)
- 지표: 요청 성공률, 평균 재시도 횟수, 밀리초 단위 요청 밀도
재시도 전략 구현
실험은 다음 세 가지 전략으로 구성했다.
1. Simple Retry
- 실패하면 즉시 다시 시도
2. Exponential Backoff
- 실패할수록 2ⁿ초 지수 백오프(delay) 적용
time.sleep(BASE_BACKOFF_SEC * (2 ** (attempt - 1)))
3. Full Jitter Backoff
- 지수 백오프에 랜덤 지연(Jitter) 추가
max_delay = BASE_BACKOFF_SEC * (2 ** (attempt - 1))
time.sleep(random.uniform(0, max_delay))
실행 구조
- Python의
ThreadPoolExecutor를 사용해 100개의 요청을 병렬 처리 - 각 요청은 실패 시 재시도하며, 요청 시각(ts_ms)과 성공 여부를 CSV로 기록
- 전략별 결과는 별도 파일로 저장 후 시각화
결과
-
Simple retry: 모든 재시도가 매우 짧은 시간에 집중되어 서버에 과부하 유발 가능성이 높음
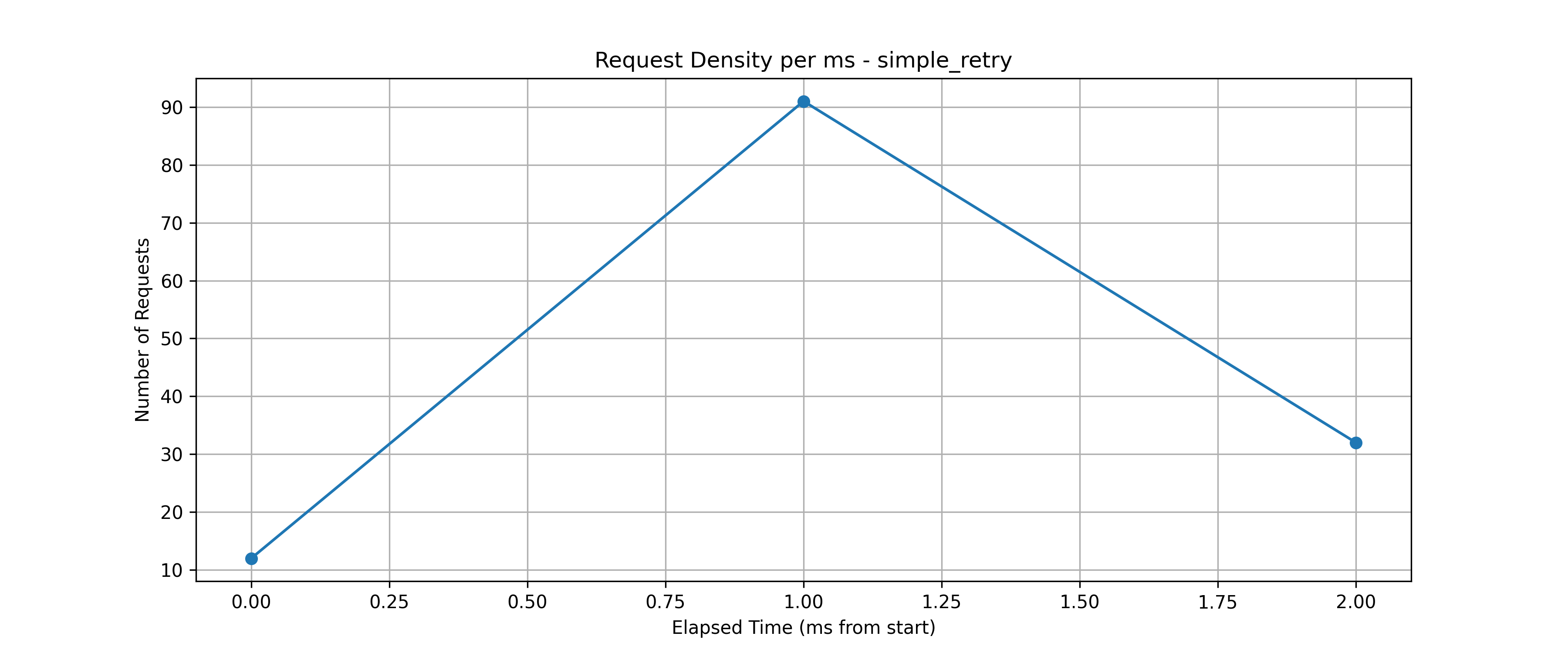
-
Exponential Backoff: 시간 간격을 두고 요청이 나뉘지만, 특정 시점에 여전히 몰림
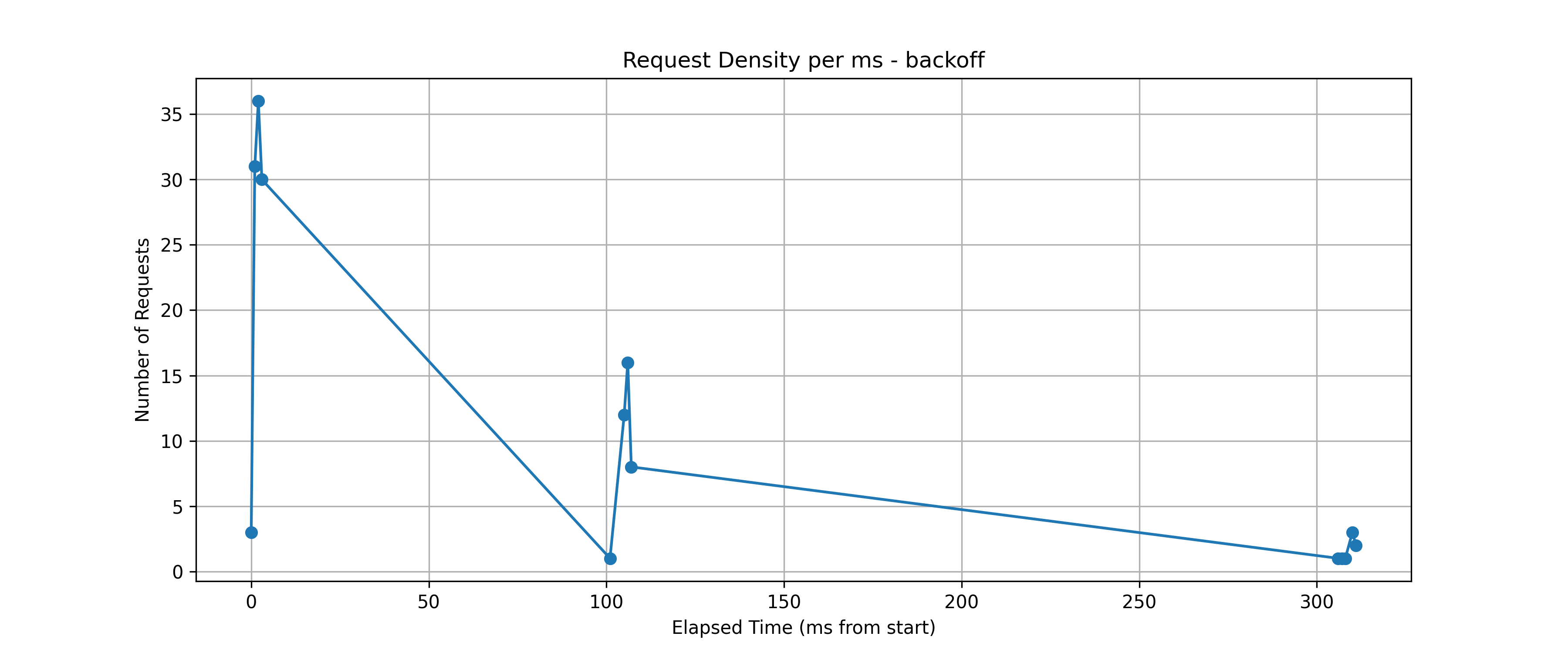
-
Full Jitter Backoff: 재시도가 랜덤하게 분산되어 전체 요청이 고르게 퍼짐
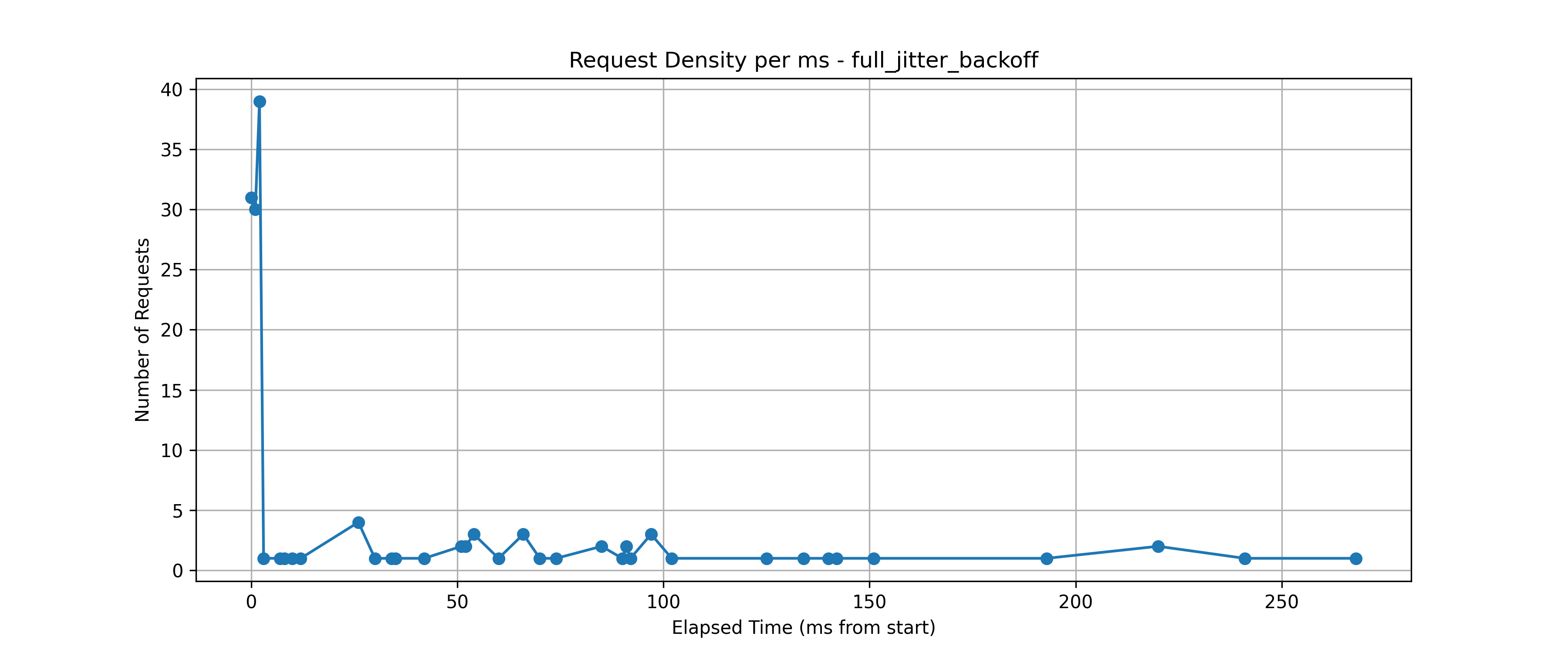

후투티(Eurasian Hoopoe)
Upupa epops
머리 위에 부채 모양의 깃털이 특징인 새로, 갈색 몸에 검은색 줄무늬 날개를 가졌다. 뾰족한 부리로 땅을 파서 곤충을 잡아먹으며, ‘푸푸푸’ 하는 독특한 울음소리를 낸다.